[자료구조] Searching
Searching
이번 포스트에서는 직렬 검색, 이진 검색, 해싱 검색 등 다양한 검색 방법을 소개한다.
Serial Search
Serial Search : 연속 검색
- 배열에서 원하는 항목을 순차적으로 검색(처음부터 끝까지)
- 항목이 발견되거나 검색이 성공하지 않고 모든 항목을 조사한 경우 검색이 중지
- 단점은 원하는 항목이 배열에 없을 경우 배열 전체를 비교해야한다.
Binary Search
Binary Search : 이진 검색
- 이진 방식으로 정렬된 배열에서 원하는 항목을 검색
- 항목이 발견되거나 검색이 성공하지 않고 모든 항목을 조사한 경우 검색이 중지
- 처음과 끝의 인덱스값을 더해 2로 나눠 검색
- 그 값과 엔트리를 비교해 좌우를 선택
- 최종적으로 엔트리값 찾아냄
Hashing
Hashing : 해싱
- 키 값을 배열 인덱스에 매핑하는 기술
- hash function(해시 함수)을 사용하여 인덱스를 결정
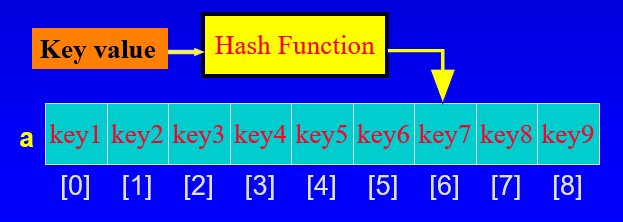
hash function example
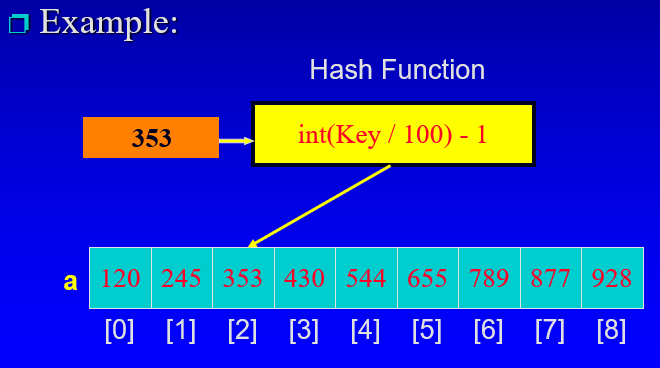
- 해싱은 데이터 저장 및 검색에 사용할 수 있다.
- 두 개의 개별 키가 동일한 배열 인덱스에 매핑될 때 충돌이 발생할 수 있다.
- 따라서 충돌 해결이 필요하다.
Open-Address Hashing
Open-Address Hashing Storage Algorithm
Open-Address Hashing Storage Algorithm : 개방형 주소 해싱 저장 알고리즘
- 키 k가 있는 레코드가 주어지면 해시 함수(예: hash(key))로 인덱스를 계산
- 만약 data[hash(key)]가 비어있으면, data[hash(Key)]에 레코드를 저장하고 종료
- 그렇지 않으면 data[hash(key)+1]가 비어 있는지 확인
- 그렇다면 거기에 기록을 저장
- 그렇지 않으면 data[hash(key)+2] 등을 시도
위 과정 예시
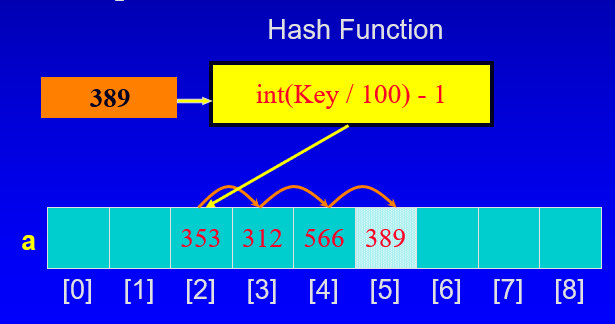
Table Class
테이블은 레코드를 삽입, 삭제 및 찾기 위한 작업이 있는 레코드의 컨테이너다.
- 백과 달리 각 테이블 작업은 단일 키 필드에 의해 제어되고
- (hash table)해시 테이블은 해시 함수가 있는 테이블이다.
Table Class Template
template <class RecordType>
class table
{
public: …
private: …
RecordType data[CAPACITY] ;
std::size_t hash(int key) const ;
…
}
Public, Private Functions for Table
Public
Constructor
- 새 개체 인스턴스를 만든다.
Insert(entryRecord)
- 테이블에 새 레코드 항목을 삽입
remove(key)
- 테이블에서 키를 포함하는 레코드를 제거합니다.
is_present(key)
- 테이블에 키를 포함하는 레코드가 있는지 테스트
find(key, found, result)
- 테이블에서 키가 포함된 레코드를 찾습니다.
- 찾은 경우 결과는 레코드의 복사본으로 설정되고 찾은 항목은 true로 설정됩니다.
- O.W., 발견은 거짓이고 결과는 가비지를 포함합니다.
size( )
Private
hash(key)
- 키를 인덱스에 매핑
next_index(index)
- 다음 (circular : 순환) 인덱스를 찾는다.
find_index(key,found,i)
- 특정 키를 가진 레코드의 배열 인덱스를 찾는다.
never_used(index)
- data[index]가 사용된 적이 없으면 true를 return한다.
is_vacant(index)
- data[index]가 현재 사용되고 있지 않으면 true를 return한다.
Private member variables for Table
NEVER_USED
- 셀이 사용된 적이 없음을 나타내는 데 사용되는 상수
PREVIOUSLY_USED
- 셀이 이전에 사용되었지만 현재 사용되지 않음을 나타내는 데 사용되는 상수
used
- 현재 배열에 저장된 레코드 수
[Q1] 배열 셀이 비어 있는지 어떻게 알 수 있습니까?
[A1] 키 필드가 특수 값으로 설정된 레코드 저장
[Q2] NEVER_USED 및 PREVIOUSLY_USED 두 개의 상수를 사용하는 이유는 무엇입니까?
[A2] not_in_use라는 하나의 상수만 사용한다고 가정하면, insert를 여러개하고 그중 중간 값 몇개를 삭제하면 find할때 중간값이 not_in_use라서 찾을 수 없다. 따라서 PREVIOUSLY_USED를 만나면 게속 검색
constructor
- 각 배열 구성 요소의 키 필드를 NEVER_USED로 설정
- Sets used to 0
Hash Funtions
Division Hash Functions(나누기나머지)
- 일반적으로 key % table_size를 계산
- 좋은 table_size는 4k+3 형식의 소수다.
Mid_Square Hash Functions(중간사각형)
- key * key의 중간 숫자(2진수)를 가져온다.
- Ex : table size = 256, key = 157
- 4라는 index에 hash값을 저장
Multiplicative Hash Functions(곱하기)
- *키의 처음 몇 자리를 취함(0 < a < 1)
- Ex : key = 157, a = 0.0234521
Types
Linear Probing(선형 프로빙)
- location hash(key)가 비어 있지 않으면 빈 자리를 찾을 때까지 hash(key)+1, hash(key)+2, hash(key)+3 등을 시도
Double Hashing(이중 해싱)
- 선형 프로빙은 클러스터링 문제로 인해 삽입 시간이 더 오래 걸리기떄문에 이중해싱 사용
- 위치 해시(키)가 비어 있지 않으면 두 번째 해시 함수(이중 해싱)를 사용하여 단계 길이(얼마나 앞으로 이동해야 하는지)를 결정
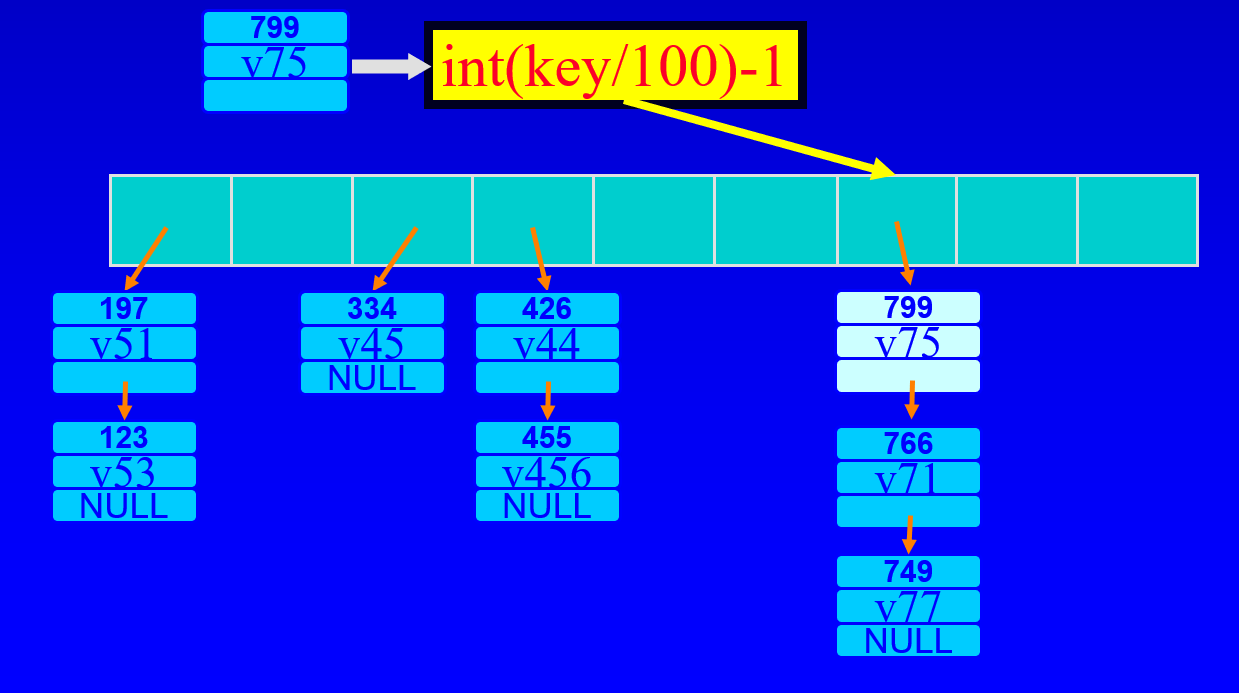
Chained Hashing(체인 해싱)
- 각 배열 구성요소는 둘 이상의 항목을 보유할 수 있다.
댓글남기기